
こんにちは。アイティーシー DA事業部の岡です。前回に引き続きKaggle活動記録を掲載します。
Kaggleについて
前回のブログ記事をご覧ください!
今回ご紹介するコンペティション
Tabular Playground Series-9月版
コンペティション内容詳細
今回ご紹介するコンペティションは機械学習モデルを構築したことがある方にとってはお馴染み、特定商品の販売点数予測です。評価関数はSMAPE(対称平均絶対パーセント誤差)。過去4年間(2017年~2020年)の売上データを学習データとし、次の1年間(2021年)の売上点数を予測します。
今回のコンペティションのポイント
この題材(商品販売点数予測)は、TabularPlaygroundSeries-1月版ととても似ています。
前回と比較し、データ状態として違うのは、「予測商品点数が増えていること」と、「予測する国の数が増えていること(国毎、店舗毎の売上店数を予測します)」が挙げられます。
また、外的要因により前回と大きく違うところは、2020年流行した新型コロナの影響です。2022年1月コンペは、2019年の1年間の売上予測でしたが、今回は学習データに2020年のデータが含まれ、予測対象が2021年の1年間、なので、新型コロナの影響がかなり大きいです。後述しますが、売上数の時系列推移を見ると2020年を境に売上点数推移が大きく変動していることが分かります。今回の分析ポイントは、一見一貫性がないように見える時系列データを元に予測を行うモデルを作成するためにどのようなアプローチ、考え方が出来るのか?というところだと思います。以降、今回のコンペで岡のアプローチについて記載しますが、Kaggleページにてコード付きNotebookを公開しているのでよろしければご確認ください。
データ状態を確認
前回補足したとおり、データを確認⇒特徴量を追加した学習データの作成⇒モデルの構築、の順で予測モデルと予測値を作成していきます。
①単純な日毎の販売数の推移から確認していきましょう。横軸が時間軸、縦軸が販売数で1日の合計販売数の平均をプロットした図が↓です。2019年までは年末年始に突出して販売数が増加していることと、2020年がそれまでと比べて明らかに推移傾向が違うことが分かります。

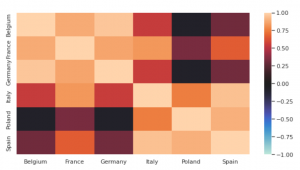
②予測する国同士の日毎販売数の相関をヒートマップ↓で確認。どうも「ドイツ・フランス・ベルギー」と、「イタリア・ポーランド・スペイン」の2グループに分かれて、3カ国ずつで高い相関がありそうです。※2020年のデータも含んだ状態=コロナの影響を反映したとしても相関が高いということで、上記2グループ内ではコロナによる商品販売数への影響が同じである推察します。
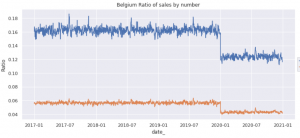
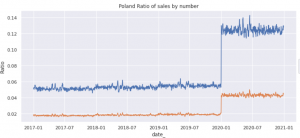
③国別かつ店舗別に横軸を時間軸、縦軸を販売数としたグラフを見ていきます。予測する6カ国の中で一番極端な傾向にあった2カ国のみを↓に表示します。ベルギーが2020年以降、それまでと比較し販売件数が減少し、逆にポーランドは販売件数が増加していることが分かります。他の4カ国の傾向も、上記②図の相関が同じグループ同士で同じ傾向(2020年以降がそれまでと比べて増加or減少している)であることが確認できました。※相関が高いもの同士で同じ傾向なので想定通りです。
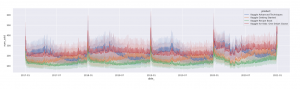
④上記①の販売数の推移を商品プロダクト毎に分けて見ていきます↓。横軸、縦軸は①と同じで、プロダクト毎に色を分けています。プロダクトが違えば、販売数の時間軸に対する推移が違うことと、2020年の、特にコロナによる影響が大きかったと思われる、大体2020年2月~6月にかけては、プロダクトが違っても変動傾向が同じであることが確認できました。
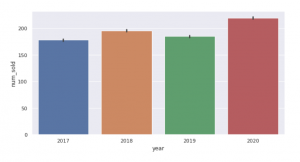
⑤全体での年毎の販売数推移は↓の通り。コロナにより販売数が減ったのかと思ったら逆で、2020年が一番販売数が多かったです。
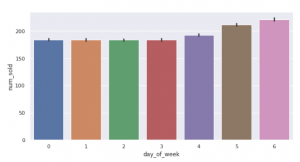
⑥曜日毎の販売数も見てみましょう。横軸の0が月曜日~6が日曜日です縦軸は1日ごとの販売数の平均値です。曜日毎で販売数に違いがでそうなことはなんとなく想像出来ますし、週末にかけて、金土日曜日の販売数が多いことはまぁその通りかなといった感触です。
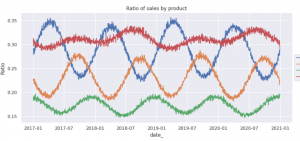
⑦同じコンペに参加していた別の参加者さんがとても良い特徴量を見つけてくださったのでそちらも追加。詳しくはこちらをご参照ください。1日ごとの販売数の合計(国別、商品別を全てあわせた合計値)を分母、商品毎の販売数合計値を分子とした割合を時系列で並べると、2017年~2019年と変わらず、2020年も同じような、連続的な傾向が確認できるのです。これは素晴らしいです。時系列データというと、連続的な傾向を元に次の値を予測するという特色が強いですが、上記①や③、④をみると明らかに連続的ではなく、どのように特徴量として重み付けをしていこうかと悩んでいたところでした。↓を見る限り、どのプロダクトも2年周期で傾向が変化してそうです。
学習データを準備
色々なデータ状態、傾向を確認したところで学習データを作成していきましょう。
●提供データのうち、ラベルデータをカラム毎にscikit-learnのOrdinalEncoderを用いて数値データに変換
●日付データを年、月、日のデータに分割して追加
●上記②から、相関が高いもの同士の2グループに分けて平均や個別で先に予測した値を特徴量として入れても良さそう
●上記⑥から、曜日ラベルも追加
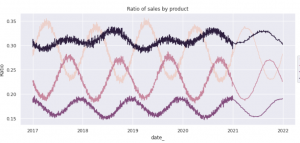
●⑦より、↑でプロットしたデータを用いて、軽めのRegressionで求めた2021年1年間の割合推移(↓図の2021年区間)を特徴量として追加。2017年~2020年は実際のデータなので、予測値が連続的に求められていることが分かります。)
●なんとなく各国のGDPデータも追加してみる
いざ学習&コンペの結果
学習データが準備できたところで、後はモデルのアルゴリズムを選定し、学習するのみです。時系列データといえば、でお馴染み、LSTMを利用したモデルも検討しましたが、2020年の推移がそれまでと極端に違うことから多分今回はそれだとうまくいかないだろうと思い、単純にLGBMとCatboostのReggressorにて学習。スコアは約8.4でした。(ちょうど中間あたりの順位。平々凡々です。)コンペ1位の方はスコア4でした。因みにコロナの影響がないバージョンの2022年1月コンペの1位スコアが4.5なのでこれより良い結果。データが違うといえど、本当にすごい…
考察
データ確認⑦図より、周期性が確認できた時点で、フーリエ変換を用いた特徴量を追加することも可能でしたが、ちゃんと理屈を理解していないままに追加するのはどうかなぁ、、ということで今回は追加しませんでした。これを追加したらもっと良いスコアが期待できたかも知れません。また、驚きだったのは、上記で同じことを記載しましたが、2022年1月のコンペ1位スコアより、今回のコンペ1位スコアの方が良いということです。詳しくは確認していませんが、学習データボリュームとバラエティーが前回より増えていたことも、スコアが良くなった要因のひとつではないかなと考えています。何にせよ、素晴らしい!また、どうしても解せないのが、国毎にコロナにより販売数が減ったり、増えたりと明らかに傾向が違うことです。これなんでなんでしょうか…人口が1年で極端に増減することはないですし、国の政策(コロナに対する補助とか?)が違うからでしょうか…?GDP以外に、CCIなど、他の経済指標も特徴量として追加してみましたが、予測値スコアを大きく上げるような特徴量は見つけられずにいます。何かこの事象を説明できる要因が見つかったら本ブログ更新しようと思います。
最後まで読んでいただきありがとうございました!
————————————————–
自己紹介
所属:株式会社アイティーシー データアナリティクス事業部
経歴:約6年間、SEとして基幹システムの運用保守、開発を担当していました。
・・・データサイエンティストへのキャリアチェンジを試み、日々奮闘中です。
Kaggleアカウントページはこちら
LinkedInページはこちら