はじめまして。アイティーシーの平垣と申します。
本記事は、Python・機械学習・kaggle全くの初心者である私が取り組んだKaggleコンペティション(おなじみのTitanicですが…)のご紹介です。
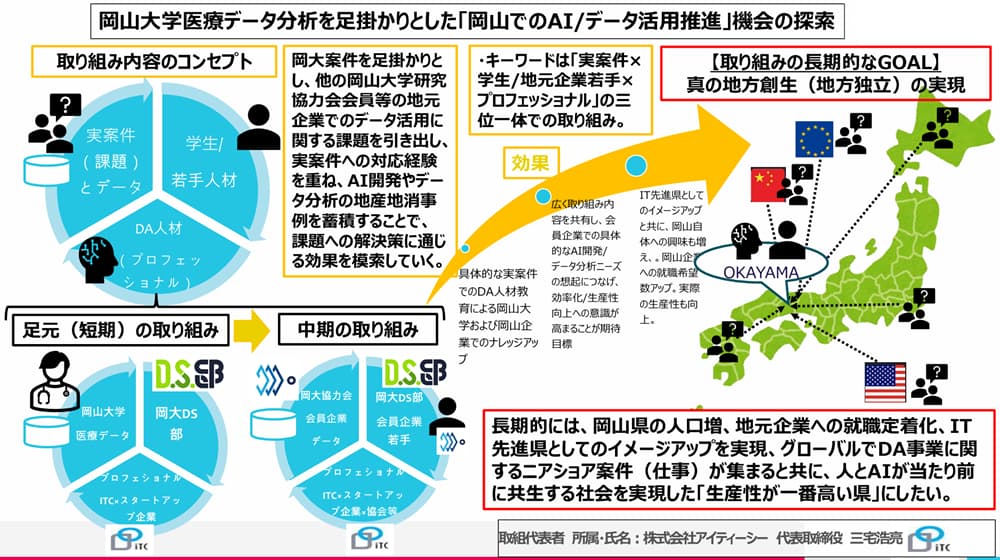
今回取り組んだコンペティション
Titanic – Machine Learning from Disaster | Kaggle
コンペティションの内容・目的
タイタニック号の遭難事故での乗客データから、誰が生存し生き残るか?を予測するコンペティションです。
乗客データは、学習用データと訓練用データに分かれており、名前・年齢・性別・社会的地位などの情報が与えられています。
生存には、運の要素のほかにもこれらの要素が関係あったと考えられていて、この問いに答える、より正確な予測モデルを作成することが目的です。
学習・分析データについて
このコンペティションの学習・分析データが以下の3ファイルです。
- train.csv(学習用の乗客データ)
- test.csv(分析用の乗客データ)
- sample_submission.csv(提出ファイルのサンプル)
各ファイル内の項目については、以下をご参照ください。
Titanic – Machine Learning from Disaster | Kaggle
実践
上述の通り私は、Pythonや機械学習については未経験ですが、Titanicのコンペでは有志の方が作成しているチュートリアルガイド(Titanic Tutorial | Kaggle)があるため、その通りに進めることでひとまず予測モデルの作成をすることができました。
<チュートリアルの内容>
チュートリアルでは、特徴量として学習用データの客室のグレード、性別、同乗している配偶者、兄弟、親、子どもの数を使用し、ランダムフォレスト・モデルを構築し、訓練用データの乗客の生存予測を行っていました。
このチュートリアルを完了して、提出した時点のスコアは0.77511でした。
<Fare(旅客運賃)の追加>
このスコアを向上するために、知識がないなりに何かできないかと考えた結果、特徴量として学習用データのFare(旅客運賃)も追加して、再構築してみることにします。
Fare(旅客運賃)を追加した理由としましては
- 高い運賃を払える人ほど、生存率が高いのではないかと仮定
- 生存率との相関係数を確認したら0.25であり、弱い正の相関があることが判明
以上2点から追加してみることにしました。
ただ、直接チュートリアルのモデルに特徴量として学習用データのFareを追加し、再構築しようしても、訓練用データのFareに欠損値が1つあり、うまくいきませんでした。
解決策について調べてみると、前処理というものが必要らしく、欠損値を埋めるか削除しないといけないそうです。
今回の場合は、欠損値が訓練用データの値なので削除はよくないだろうと考え、欠損値を埋める方向で行きます。
どの値で欠損値を埋めるか決定するために、まず訓練用データのFareの分布図、平均値、中央値を求めました。その結果、平均値と中央値の値に差があり、分布図も歪んでいたので欠損値として、中央値を用いることに決定しました。
そして、モデルを構築して再び実行。スコアは0.77751
気持ちばかりスコアが上昇しました、、、
<Age(年齢)の追加>
さすがにもう少し、スコアが向上してほしいので今度は、Age(年齢)も特徴量として追加してみることにしました。
Ageは欠損値が多くあり使いにくいなと思っていたのですが、生存率には関係があるだろうと仮定し、中央値で欠損値を補完しました。
モデルを構築し、再び実行。スコアは0.78229となりました。
前モデルよりはスコアの上昇が見られたのでやはり年齢は重要な要素であるのかなと予測できます。
所感
その後も、特徴量全部追加(スコアは減少)やAge・Fareの欠損値を平均値で追加(スコアは上昇)などを行いましたが、いずれも微々たる変化でした。
よりスコアを上昇するには、きちんと学習して、前処理やデータの加工方法、新たな分析モデルについての知識を吸収する必要性を感じました。
今回、初めてTitanicのコンペティションに参加しましたが、噂通り機械学習やkaggle初心者の方にとてもおすすめです。
チュートリアルでモデルの作成をするので、知識がなくてもその土台の上で自分なりにモデルの再構築が行えます。
また、スコアという目に見える形で結果がわかるのでモチベーションを保ちやすいのもいい点ですね。
以上で本コンペティションの取り組みは終了とします。
今回作成したコードはこちら(My first Titanic | Kaggle)
最後まで拝読頂き、ありがとうございました。
今後も精進してまいりますのでまたの更新をお待ちください。